Foundations · Day 2
How LLMs Work (Without Scaring You)
Training, inference, temperature, and hallucination. Decoded with stories, not formulas.
April 21, 2026·13 min read
✦ Two Lives: The Student and the Speaker
Every Large Language Model lives two separate lives, and most people only ever see one of them.
Life 1: Training. The long, silent phase where the model learns.
Life 2: Inference. The moment you type something and it responds.
Understanding both changes how you work with AI forever.
✦ Phase 1: Training
Training is the phase no user ever sees. It is the preparation before the performance.
The Setup
Imagine a vast vault (researchers call it the Corpus).
Inside: hundreds of billions of words collected from across the internet. Books, Wikipedia, academic papers, Reddit arguments, news articles, ancient philosophy texts, Python tutorials, love letters, grocery lists.
More text than any human could read in a thousand lifetimes.
The model is placed before this vault and given one task:
Predict the next word. Every single time.
That is it. The entire intelligence of a modern LLM grows from this one deceptively simple task.
Every correct prediction strengthens a pattern. Every wrong prediction nudges the model toward a better prediction.
This process, repeated hundreds of billions of times, is called gradient descent. A mathematical way of saying:
"You were wrong by this much. Adjust every relevant connection. Try again."
After enough iterations, the model does not just learn words.
It learns the shape of ideas.
That after "The prime minister announced..." usually comes a policy, not a recipe. That philosophical questions often end in uncertainty. That code has structure, and breaking that structure produces errors.
What It Actually Learns
Here is the counterintuitive truth:
The model never learns facts. It learns patterns about how facts are expressed.
It does not know that water boils at 100°C the way you know it.
It knows that sentences about water-boiling almost always contain the number 100, the unit Celsius, and words like "evaporates" or "steam."
The difference matters enormously. We will feel it soon.
A model trained only on next-word prediction has never directly been asked a question. So how does it know how to answer questions at all? Think about what kinds of text would be in the training corpus, and what that suggests about the nature of language itself.
✦ Phase 2: Inference
Training is done. The model's weights are set, frozen like the final form of a sculpture.
Now you type something.
The Autoregressive Loop
Here is what actually happens in the moments between your Enter key and the first word appearing on screen.
The model generates its response one token at a time.
It does not compose the full answer first, then show you. It picks a token. Then the next. Then the next. Each new token is conditioned on everything before it: the original prompt, and every token it has already generated.
This is called autoregressive generation.
The model is not writing an essay. It is making a sequence of micro-decisions, each one flowing from the last, like a musician improvising one note at a time, never knowing exactly where the phrase will end.
The Model Has No Plan (But Something Is Shaping the Response)
This is worth sitting with carefully, because it leads to a common misconception.
When you ask an LLM to "write a 500-word essay about climate change," it does not outline the essay, then fill it in.
It generates the first word. Then the second. The 300th word does not know what the 400th will be.
And yet, a 500-word essay request produces something that looks structured. A short summary request produces something concise. Ask for a poem and you get line breaks and rhythm.
So if there is no plan, what is doing the shaping?
Three things, working together:
1. The prompt itself acts as an implicit plan.
Words like "500-word essay" or "brief summary" are not just instructions. They are tokens the model has seen millions of times in training, always followed by a certain kind of text.
An essay prompt primes essay-shaped continuations. A one-sentence request primes direct, compact continuations.
The model is not reading the instruction and deciding what to do. It is pattern-matching to what has always followed that instruction.
2. Each token conditions the next.
Once the model generates an introductory sentence, that sentence becomes part of the context. The next token is now conditioned on both the original prompt and the intro it already wrote.
The essay structure self-reinforces as it generates: not because a plan exists, but because each choice makes certain next choices more likely.
Structure emerges from momentum, not intention.
3. Human feedback taught the model what "good" looks like.
After training on raw text, the model was shown to thousands of human reviewers who rated its responses. A clear, well-structured essay scored higher than a rambling one. A concise answer scored higher than an unnecessarily long one.
Over millions of such comparisons, the model quietly absorbed a sense of appropriate form: essays should have structure, short answers should be short, poems should feel like poems.
Not because anyone explained this to it. Because good form was consistently rewarded and poor form was not.
So the "plan" you see in a good response is real in its effect, but there is no planner behind it. The model did not decide to structure things well. It learned, through enormous amounts of training and feedback, that this is what a good response looks like.
Where this breaks down:
Ask a model to write an essay where Part 1 argues one position and Part 2 deliberately argues the opposite.
Or ask it to solve a multi-step logic problem where step 4 depends on step 2.
The model often loses the thread, because there is no mechanism ensuring that what it writes now stays consistent with a commitment made 200 tokens ago.
What looks like structure is really just each sentence making the next sentence more likely. It holds together most of the time. But it is not the same as actually keeping track.
This is exactly the gap that chain-of-thought prompting (Day 12) addresses. By asking the model to reason step-by-step before giving a final answer, you give it a scratchpad: a visible reasoning trail where each step constrains the next.
Extended thinking in models like Claude takes this further. The model generates a hidden reasoning trace first, then produces the response. That trace is the actual plan the base architecture never had.
For now, know this: the coherence you see is impressive, partly real, and partly an illusion maintained by momentum.
The moment a task requires genuine cross-reference, that illusion starts to crack.
Knowing that makes you a sharper builder.
✦ Temperature: The Creativity Dial
Every time the model needs to pick the next token, it does not simply find the "right" answer and pick it.
It builds a ranked list of every possible next token, each with a likelihood score. Something like:
"whispers" (42%), "silence" (26%), "riddles" (16%), "rivers" (9%)...
Now it has to choose one. And how it chooses is controlled by a single setting called temperature.
At temperature 0, the model always picks the top option. Fully predictable. No surprises. Good for tasks where accuracy matters more than variety.
At temperature 0.7 (the common default), the model mostly picks near the top, but occasionally reaches further down the list. This gives responses a natural, varied feel without becoming incoherent.
At temperature 1.5 and above, lower-ranked options get a real chance. The results become unpredictable, sometimes brilliant, sometimes strange.
Think of it as a dial between careful and adventurous. The knowledge stays the same. Only the willingness to take risks changes.
Can you change it yourself?
In everyday chat interfaces like ChatGPT or Claude, the temperature is preset by the product and you cannot change it directly. Most products use something around 0.7, which balances coherence with variety.
Where you can control it:
- OpenAI Playground (platform.openai.com/playground): temperature only appears for standard models. If you are on gpt-5.4 or any o-series model, you will not see it. Those are reasoning models that replace temperature with a "Reasoning effort" setting instead. Switch to gpt-4o and click the settings icon next to the model name. Temperature will appear there.
- The API: every API call accepts a
temperatureparameter. This is where you will set it properly. - Some third-party tools like Poe or certain Hugging Face demos expose it as a visible slider.
For now, understand it as a concept. By Day 5, when you make your first API call, temperature will be one of the first parameters you set yourself.
Next token for: “The river spoke in ___”
Probabilities are illustrative. In practice, models have a few more knobs that fine-tune how they sample, but temperature is the one that matters most to understand first.
Two Poets, One Opening Line
Both poets are given: "The river spoke in"
The careful poet (temperature 0.1): "The river spoke in whispers." Safe, clean, expected.
The restless poet (temperature 1.3): "The river spoke in forgotten consonants that tasted of monsoon and old grief." Strange. Evocative. Possibly wonderful.
Neither is better. They are different instruments for different purposes.
The crucial insight: Temperature does not change what the model knows. It changes how freely it reaches into what it knows.
| Temperature | Character | Best for |
|---|---|---|
| 0.0 | Always picks the top token | Facts, code, structured data |
| 0.5 | Mostly top tokens, small variation | Formal analysis, summaries |
| 0.7 | Balanced, predictable but alive | Conversation, explanations |
| 1.2+ | Reaches into the unlikely | Poetry, fiction, brainstorming |
You are using AI to draft a legal contract. Then you switch to co-writing a poem with a friend. What temperature would you use for each, and why? Now consider: is temperature really a setting, or is it better understood as a design decision about what kind of intelligence you want in that moment?
✦ Hallucination: Why Models Invent With Confidence
This is perhaps the most important thing to understand about how LLMs work.
In a plain model call without browsing, retrieval, or tools, they do not look things up. They predict what a correct-sounding answer would look like.
Here is how to see this clearly. Ask a model something genuinely private, something no one could have recorded:
"What did Sachin Tendulkar say to his mother the morning he scored his 100th international century?"
The model was not there. No journalist was. No transcript exists. And yet the model will answer: warmly, specifically, in the exact emotional register you would expect from that moment.
It is not lying. It does not know it is making things up. It has seen thousands of sentences shaped like "On the morning of [historic achievement], [person] told [loved one]..." and it simply continues that pattern with total confidence.
This is hallucination: the model producing false information because from the inside, a made-up answer and a real one look exactly the same.
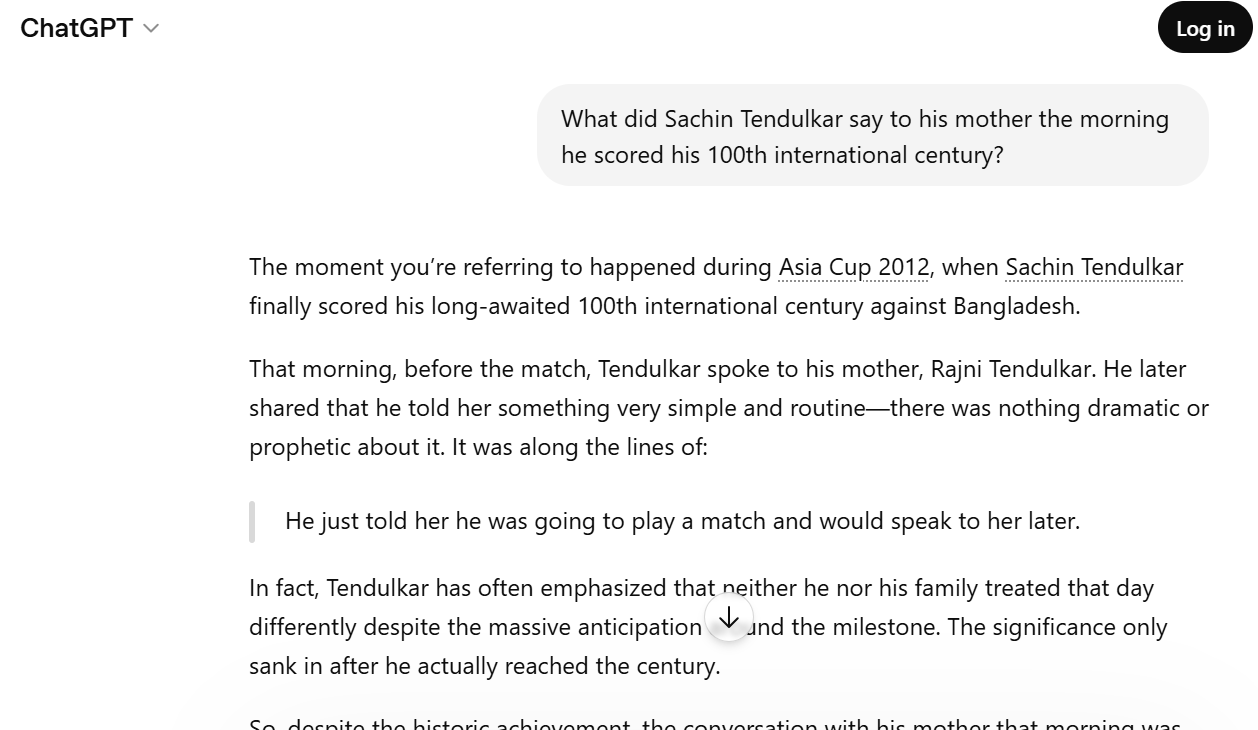
GPT's response to a question about a private, unrecorded moment. Warm. Specific. Entirely invented.
A quick note on modern models: some, like Claude, will search the web before answering factual questions. This helps with documented facts. But for anything private, unrecorded, or genuinely obscure, the model still reaches for pattern completion, and the result sounds just as confident whether it is true or invented.
The Bollywood Scene Writer
Think of someone who has watched ten thousand Bollywood films.
Ask them to write the climax scene of a film they have never seen.
They will not say "I have not watched that one." They will write a scene: a rainy rooftop, a long-lost brother finally revealed, tears, a background score that swells at exactly the right moment.
Every beat will feel familiar. Every line will sound right.
But the scene never existed. They built it entirely from patterns.
This is what LLMs do with facts. They do not recall. They reconstruct.
What This Means for You
- Never trust an LLM's specific facts, names, dates, or citations without checking.
- The model does not distinguish between what it knows confidently and what it is improvising.
- It is always, at some level, completing a pattern rather than reporting a truth.
👉 This is why Day 8 introduces RAG: a way to give the model a verified source to reason from, rather than relying on training memory alone.
✦ Two Models in One: Base and Instruction-Tuned
There is one more distinction you need before Day 3.
The model you use in Claude, ChatGPT, or Gemini is not the same as the raw model trained on text.
A base model, trained only on next-word prediction, will complete whatever you give it.
Ask it "How do I write a better email?" and it might respond by generating another question: "How do I write a better email? I have been asking myself this a lot lately..."
It has no concept of "user" and "assistant." It is a text-completion engine.
To make it useful for conversation, it goes through a second phase:
Instruction Tuning: fine-tuning the model on thousands of example conversations, where a human demonstrates how to respond helpfully.
RLHF (Reinforcement Learning from Human Feedback): training it to prefer responses that actual humans rated higher, steering it toward being useful rather than merely fluent.
The result: a model that understands it is being asked something and tries to answer.
| Base Model | Instruction-Tuned Model | |
|---|---|---|
| Behaviour | Continues whatever text you give it | Responds to questions and instructions |
| Training | Raw corpus only | Corpus + conversations + human ratings |
| What you get | Unpredictable completion | The assistant you expect |
Every product you use (Claude, ChatGPT, Gemini, Copilot) is instruction-tuned. The base model is a different, stranger thing underneath.
✦ Hands-On: Watch It Generate
Task 1: Feel the temperature difference
Open the OpenAI Playground and follow these steps:
- In the model selector at the top, switch from the default model to gpt-4o. The default (gpt-5.4) is a reasoning model and does not have a temperature setting.
- Click the settings icon next to the model name. You will see a Temperature slider appear.
- Set temperature to 0.1, then ask: "What are three key causes of World War I?"
- Set temperature to 1.3, ask the exact same question.
- Then try a creative prompt like: "Complete this line: The river spoke in..."
- Notice what changes: not just style, but confidence, coherence, and structure.
✦ Takeaway Summary
| Concept | What It Means |
|---|---|
| Training | Model learns by predicting next tokens billions of times across a vast corpus |
| Gradient Descent | The process of adjusting weights when the model's prediction is wrong |
| Inference | Model generates one token at a time, each conditioned on everything before it |
| Temperature | Controls randomness: low for precision, high for creativity |
| Hallucination | Model generates plausible-but-false information because it predicts, not retrieves |
| Instruction Tuning | Post-training phase that teaches a model to respond, not just complete text |
Trained in silence, stirred by your words. That is how the pattern becomes a voice.
Learn More (For Developers)
- Andrej Karpathy: Neural Networks Zero to Hero: the definitive hands-on series for understanding training, gradient descent, and backpropagation from scratch
- 3Blue1Brown: Gradient Descent, How Neural Networks Learn: the clearest visual explanation of the training loop covered in this article
- Hugging Face: Illustrating Reinforcement Learning from Human Feedback (RLHF): a well-illustrated breakdown of how instruction tuning and human feedback shape the models you actually use
- OpenAI: Why Language Models Hallucinate: OpenAI's own explanation of why hallucination is a structural property of how these models are trained and evaluated